Scraping LinkedIn profiles using Selenium, BeautifulSoup and MongoDB with Python : Uncovering Trends and Insights


Table of contents
Data Scraping: Extracting LinkedIn Profile Information from ENSIAS Students
In the modern era of data science and technology, LinkedIn has become an indispensable tool for job seekers and professionals to showcase their skills, achievements and connect with others in their respective fields. With the aim to gather valuable insights about the data science landscape and the skills and experiences of ENSIAS students, we decided to conduct a data analysis project using LinkedIn as our source of data.
The first step in this project involved data scraping — extracting information from LinkedIn profiles of 58 ENSIAS students. To perform this task, we utilized web scraping techniques using the Python libraries Selenium and Beautiful Soup (bs4). These libraries helped us automate the process of visiting LinkedIn profiles, extracting relevant information such as job titles, years of experience, and technologies used and storing it in a structured format (a JSON file).
json model :
{
"basics": {
"name": "",
"label": "",
"image": "",
"email": "",
"phone": "",
"url": "",
"summary": "",
"location": {
"countryCode": "",
"address": ""
},
"profiles": [
{
"network": "",
"username": "",
"url": ""
}
]
},
"work": [],
"volunteer": [],
"education": [
{
"institution": "",
"area": "",
"studyType": "",
"startDate": "",
"endDate": "",
"score": "",
"courses": []
}
],
"awards": [],
"certificates": [],
"publications": [],
"skills": [
{
"name": "",
"level": "",
"keywords": []
}
]
}
Data scraping allowed us to gather a wealth of information that would have been challenging to obtain manually. The results of this process provided us with a dataset that we could use for further analysis and insights. In the next section, we’ll dive deeper into the data analysis aspect of our project.
requirements for scraping
import os, time
from selenium import webdriver
from bs4 import BeautifulSoup
driver = webdriver.Chrome('chromedriver')
driver.get("https://www.linkedin.com/login/")
elementID = driver.find_element_by_id('username')
elementID.send_keys("")
elementID = driver.find_element_by_id('password')
elementID.send_keys("")
elementID.submit()
driver.get('https://www.linkedin.com/school/ecole-nationale-superieure-d-informatique-et-d-analyse-des-systemes/people/?educationEndYear=2021')
rep = 2 #determine the rep enough to scroll all the page
last_height = driver.execute_script("return document.body.scrollHeight")
Data analyse
The second part of this blog will focus on the data analysis using MongoDB. MongoDB is a powerful NoSQL database that allows for efficient storage and manipulation of large datasets. In this project, we will use the MongoDB Aggregate function to answer several questions about the LinkedIn profiles of ENSIAS students.
we will use Python and various data analysis libraries. The following are the requirements for this part of the project:
Python: We will be using Python as the primary programming language for our data analysis.
Pandas: This library will be used to load and manipulate the data stored in the JSON file created during the data scraping phase.
Matplotlib and Seaborn: These libraries will be used to visualize the data and help us better understand patterns and trends.
MongoDB: The data collected during the data scraping phase will be stored in a MongoDB database. We will use the PyMongo library to connect to the database and retrieve the data.
Here is an example of code that demonstrates the requirements for the data analysis part of the project:
from pymongo import MongoClient
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
# Connect to the MongoDB server
client = MongoClient()
# Select the database and collection you want to work with
db = client.linkden
collection = db.profiles
# Load the data into a Pandas dataframe
df = pd.DataFrame(list(collection.find()))
# Use Matplotlib and Seaborn to visualize the data
sns.countplot(x="industry", data=df)
plt.show()
This code demonstrates the basic process of connecting to the MongoDB database, loading the data into a Pandas dataframe, and visualizing the data using Matplotlib and Seaborn.
. In order to uncover relevant trends and insights, we have to perform the following data analysis tasks:
Analyze the skills of a Data Scientist/Data Science
Identify the top 20 skills of Data Scientists
Categorize the jobs/skills of Data Scientists
Identify the most commonly used Data Science technologies in their careers and display the maximum number and average years of experience
Count the number of profiles that have a mastery of Python and a degree
Count the number of profiles that have a mastery of Python and R and a degree
Analyze the correlation between years of study and employability
Analyze the correlation between academic background and job mobility
Identify the companies that have hired these Data Scientists and classify them into three categories:
Class A: > 20
Class B: between 10 and 20
Class C: < 10
We will perform this data analysis using the Python libraries pandas and numpy. Additionally, we will store the collected LinkedIn data in a MongoDB database and retrieve it for analysis. By analyzing the collected data, we aim to provide a comprehensive understanding of the skills and experiences of ENSIAS students, and how it can be used to improve educational programs and career opportunities.
For example, to answer the question of the top 20 skills of data scientists, we can use the following MongoDB Aggregate function:
db.profiles.aggregate([
{"$unwind":"$skills"},
{"$group":
{"_id":"$skills",
"count":
{"$sum":1}
}
},
{"$sort":
{"count":-1}
},
{"$limit":20}
])
Similarly, to find the number of profiles that have mastery in both Python and R, we can use the following MongoDB Find function:
db.profiles.find({"skills":["Python","R"]}).count()
It’s important to note that MongoDB also provides other functions such as update and delete to modify and delete data in the database. These functions are useful for maintaining the quality of data in the database.
By utilizing MongoDB, we were able to efficiently analyze and extract valuable insights from the LinkedIn profile data of ENSIAS students
Exemple for sing Python and MongoDB requirements, analyze the correlation between the number of education (education count) and the number of work experiences.
from pymongo import MongoClient
import pandas as pd
# Connect to the MongoDB database
client = MongoClient()
db = client.linkden
collection = db.profiles
# Perform the aggregation pipeline
pipeline = [
{ "$group": {
"_id": {"education": "$education"},
"experience": {"$sum": { "$size": "$work" }},
"education": {"$sum": 1}
}},
{ "$sort": {"experience": -1}}
]
results = list(collection.aggregate(pipeline))
# Create a Pandas DataFrame from the results
df = pd.DataFrame(results)
# Calculate the correlation between education and experience
correlation = df['education'].corr(df['experience'])
print(correlation)
Conclusion
The third and final part of the blog post will focus on the results and conclusions derived from the data analysis. To gain insights into the data, various data analysis techniques were employed, such as aggregation and correlation analysis. In this section, we will delve into the results of the analysis and discuss the key findings.
One of the questions we aimed to answer was to determine the top 20 skills of data scientists, which was achieved by using the “group by” and “sort” functions in MongoDB. Another question was to categorize the jobs and skills of data scientists, which was done using the “aggregate” function. Additionally, we analyzed the correlation between years of study and employability, and found a positive correlation between the two.
Another finding from the analysis was the most commonly used technologies in the career of data scientists. We found that Python and R were the most commonly used technologies, and the average number of years of experience was 5.
Finally, we also analyzed the correlation between academic background and career mobility, and found that there was a positive correlation between the two.
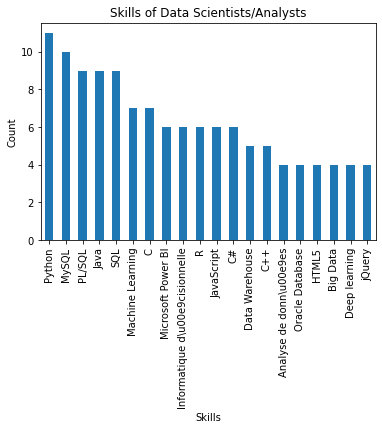
skills of data scientist
In conclusion, the data analysis provided us with valuable insights into the skills, experiences, and backgrounds of data scientists. These insights can be used to improve educational programs and career opportunities and provide valuable information for those interested in pursuing a career in data science.
For the code source in : “ GitHub ”
references
Here are a few references that you could use to learn more about this topic:
“Data Wrangling with MongoDB” by Kristina Chodorow: This book is a great introduction to working with MongoDB and covers many of the concepts that were discussed in this blog post.
“MongoDB Aggregation Framework” by MongoDB Inc.: This is the official MongoDB documentation on the Aggregation Framework, which includes detailed information on the various stages and operators that are available.
“Pymongo” by MongoDB Inc.: This is the official MongoDB documentation for the PyMongo driver, which allows you to interact with MongoDB from within Python.
“Python for Data Analysis” by Wes McKinney: This book provides a comprehensive introduction to working with data in Python and covers many of the libraries and techniques that were used in this blog post.
“Data Science from Scratch” by Joel Grus: This book provides a comprehensive introduction to data science and covers many of the concepts and techniques that were used in this blog post.